Jak efektivně využít expirované domény pro SEO
25/7/2017
Expirované domény. Věčné téma lidí, kteří dělají v online marketingu a SEO je z části živí. V dnešním článku bych rád ukázal jak je využít co nejefektivněji při tvorbě Vašeho webu a jako zdroj odkazů.
Expirovaná vs. nová doména
Může se zdát, že expirovaná doména vzhledem k historii a backlinkům je lepší volbou pro stavbu nového projektu, ale nemusí tomu být vždy tak. Nové domény totiž mohou daleko lépe fungovat ve fresh indexu vyhledávačů. Tzn. když se budete chtít krátkodobě protlačit na nějaké KW na přední příčky, tak to i s novou doménou může fungovat dobře.
A to zvláště v případě, kdy zvolíte jako název domény klíčové slovo. Ano, i v roce 2017 má pro určité projekty smysl kupovat domény s klíčovými slovy. O tom ale třeba jindy.
Dnes se chci věnovat expirovaným doménám. Jak jsem již zmínil, tak jejich hlavní výhodou je, že mají na internetu již nějakou historii a směřují na ně odkazy (na některé, jsou samozřejmě i expirované domény bez odkazů). Cílem tedy obvykle bývá najít takovou doménu, která má historii, spoustu kvalitní odkazů a odkazujících domén.
Kde takovou doménu hledat? V ČR využívám hlavně dAukci, Monitoruj.net nebo Reborn.domains. Za doménu s kvalitními odkazy se vyplatí zaplatit i pár tisíc korun v aukci. Pokud děláte SEO, tak stejně vrážíte tisíce nebo spíše desetitisíce korun do obsahu a linkbuidlingu.
Jak vybrat správnou expirovanou doménu?
Budeme potřebovat:
- Zjištění datumu registrace domény – https://www.whois.com/
- Mrknou se na obsah co na doméně existoval – https://archive.org/
- Podívat se na odkazující domény a odkazy – https://majestic.com/
Z těchto 3 nástrojů vytáhneme potřebná data o naší vytipované doméně.
Základní pohledy na expirovanou doménu jsou:
- Název
- Datum registrace
- Téma domény
- Obsah
- Snapshoty ve webovém archivu
- Počet odkazujících domén
- Počet odkazů
- Kvalita odkazujících domén a odkazů
Název je jasné rozhodování. Líbí / nelíbí. Pokud doménu chcete využít jen k linkbuildingu (viz. níže), tak název není až tak důležitý.
Datum registrace zjistíte snadno přes Who.is. Nikdy ne mi nepotvrdily „povídačky“ o tom, že čím starší doména tím lepší. Osobně tedy tomuto faktoru nedávám až takovou váhu.
Téma domény souvisí se snapshoty ve WayBackMachinu, tedy Archive.org. Tam je třeba si potvrdit, že se doména opravdu zabývá tématem, které chci. Pozor! Opravdu si to ověřte. Název může být někdy zavádějící.
Obsah je kriticky důležitý bod. Koukejte se, zda jsou ve WayBackMachinu vidět nějaké podstránky, které by šly zrecyklovat, upravit a znovu využít u Vašeho projektu. Například to mohou být staré články, popisky kategorií, popisky produktů, když se jedná o eshop apod.
Počet odkazujících domén, počet odkazů a jejich kvalita. Zde přichází na řadu můj oblíbený nástroj Majestic.
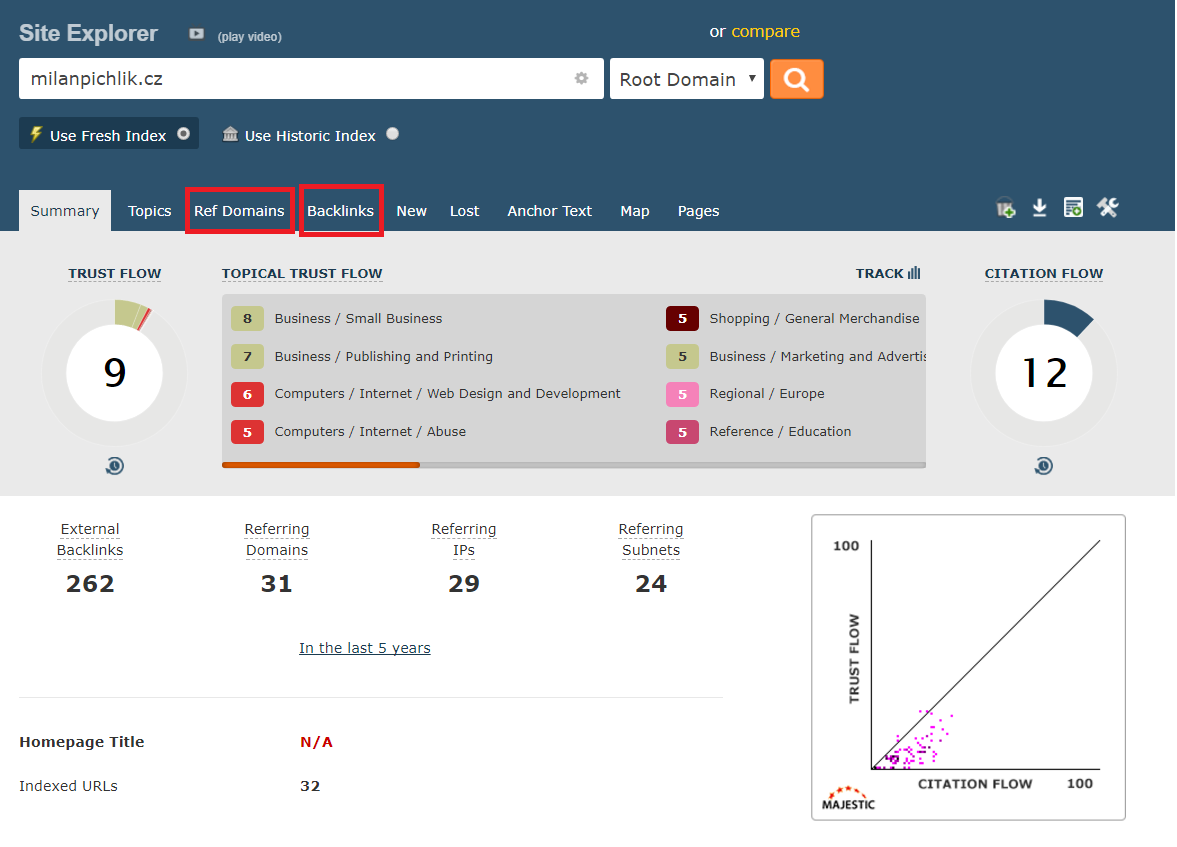
Nechci zde jít úplně do detailu, protože by to bylo na celý další článek, ale v kostce řečeno. Dívejte se na to jaké domény na Vaši vysněnou expirovanou doménu odkazují. Zda to jsou jen nějaké staré katalogy a nebo třeba iDnes, Novinky, Centrum, Seznam, Firmy apod. To může hrát nemalou roli při rozhodování, zda danou doménu koupit či nikoliv. Pro rychlou identifikaci kvality odkazujících domén používám Majestic metriky Trust Folow a Citation Folow. Odkazující domény zjistím přes záložku Ref Domains a odkazy přes záložku Backlinks.
Nesoustřeďte se však pouze na historii a odkazy. Myslete také na tématickou relevanci pro Váš projekt. Pokud chcete udělat web o nábytku, tak si nekoupíte doménu se super odkazy, kde se předtím roky prodávaly kondomy. V některých případech to sice může fungoval, ale pouze krátkodobě.
Co je trochu problém u expirovaných domén jsou jejich názvy. Pokud si koupíte expirovanou doménu a rovnou na ní postavíte projekt, tak se budete muset smířit s názvem, který doména má. Díky tomu můžete tu pravou expirovanou doménu hledat opravdu hoooodně dlouho.
Z toho důvodu je využívám spíš jako linkbuildingový nástroj. Tzn. přesměrovávám relevantní koupené expirované domény na svůj hlavní projekt. Je to taková oldschool taktika, ale spousta lidí jí pořád nevyužívá správně.
Může se to zdát jako velice jednoduchý proces. Koupíte tématickou expirovanou doménu a tu jednoduše přesměrujete na Váš hlavní web.
Jenomže tato expirovaná doména určitě měla historicky nějaké podstránky, na které vedly odkazy. Chcete všechny přesměrovat na homepage? Určitě ne. Jak však zjistíte, které všechny zaznamenané podstránky Vaše doména má? Když říkám zaznamenané, tak myslím ty, které jsou dostupné v Archive.org. Pokud nejsou zaznamenané tam, tak je velice obtížné dohledat seznam podstránek dané expirované domény.
Je však ještě jedna metoda. Pokud je doména expirované čerstvě, tak si otevřete Google a klasicky přes operátor site: nazevexpirovanedomeny.cz vyhledejte zaindexované podstránky. Třeba budete mít štěstí a naleznete tak spoustu podstránek. Ty pak můžeme zkombinovat s výsledkem, který si ukážeme v další části článku.
Rekonstrukce webu z WayBackMachinu
EDIT: Níže uvedený postup je poměrně komplikovaný a ne vždy 100%-tní. Z toho důvodu doporučuji vyzkoušet skvělý nástroj Archivarix.com, kde můžete mít vše hotové na pár kliknutí.
EDIT 2 (2019): Existuje jednodušší způsob pro získání URL adres než je popsáno níže. Stačí, když si zadáte do prohlížeče:
Následně si jen vyfiltrujete URL adresy co potřebujete.
—–
Představte si tuto situaci. Nalezli jste vhodnou expirovanou doménu, která má historii, dobré odkazy a tématicky se hodí pro Váš projekt nebo pro jeho části. Jste nadšeni a koupili jste si jí.
Jakým způsobem postupovat, aby jste opravdu přesměrovali každou podstránku expirované domény na vhodné podstránky u Vás na webu? Případně, když stavíte ihned na této doméně nový projekt, jak co nejlépe napasovat jednotlivé URL adresy expirované domény na Vaši navrženou architekturu webu?
Nejvíce se mi osvědčila metoda kompletní rekonstrukce webu z Archive.org.
K tomu využívám program Wayback Machine Downloader, který je volně dostupný na GitHubu. Můžete si ho stáhnout zde – wayback-machine-downloader-master. Stažený soubor si odzipujte a zkopírujte na plochu. Program jednoduše udělá to, že stáhne kompletní snapshot z Archive.org jako HTML.
Tento program je napsaný ve skriptovacím jazyku Ruby. K jeho rozběhu si tedy musíte Ruby stáhnout k Vám do PC. Zde je možné stáhnout verzi pro Windows.
(Malé netématická vsuvka. Vždy, když slyším název Ruby, vybavím si tohle video :D)
Instalace a práce v Ruby
Instalace je velice jednoduché. Otevřete stažený instalační soubor a dejte Next, Next, Next, Next…

Až se Ruby doinstaluje, tak ho otevřete. Nejjednodušší způsob je přes vyhledávací lištu ve Windows. Mackaři prominou, ale určitě tam máte něco podobného 🙂
Poté se Vám otevře něco co vypadá jako klasický příkazový řádek. V pořádku. To nyní bude naše pracovní plocha.
Nebojte se ničeho. Bude to jednodušší než se může zdát.
V první řadě je třeba instalovat stažený WayBack Machine downloader, který máte připravený na ploše.
K tomu je třeba tento příkaz:
gem install wayback_machine_downloader
Ten vložte do příkazového řádku a stiskněte Enter. Po pár sekundách se Vám objeví takovýto výsledek:
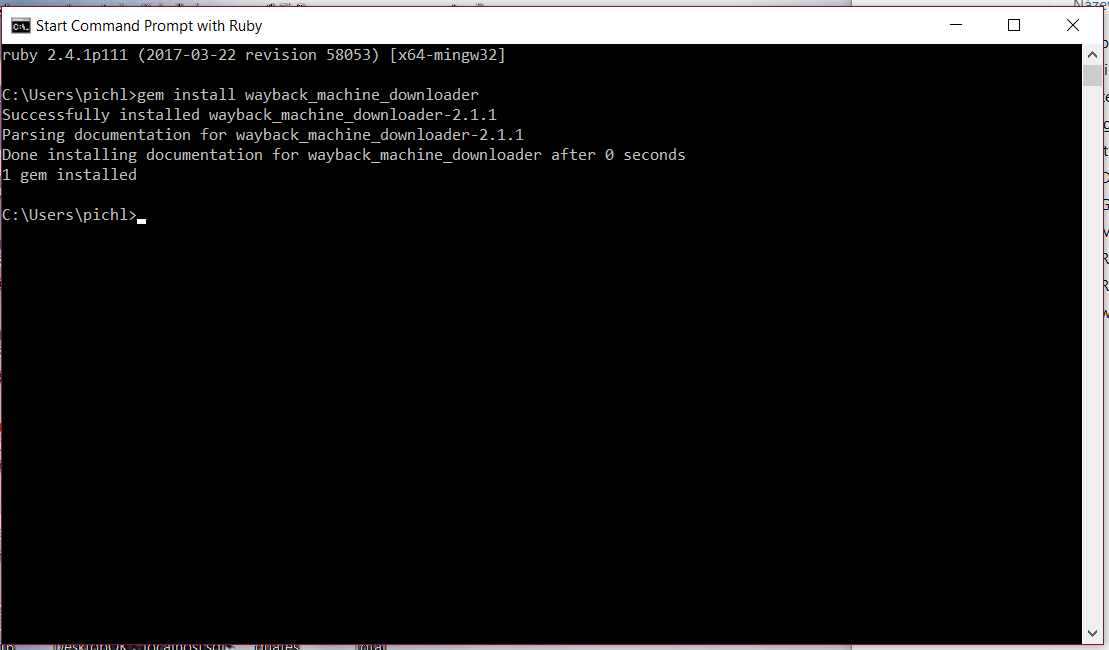
Nyní budeme potřebovat WayBackMachine. Vložte do něj Vaši expirovanou doménu a podívejte se na snapshoty, které se Vám zobrazí.
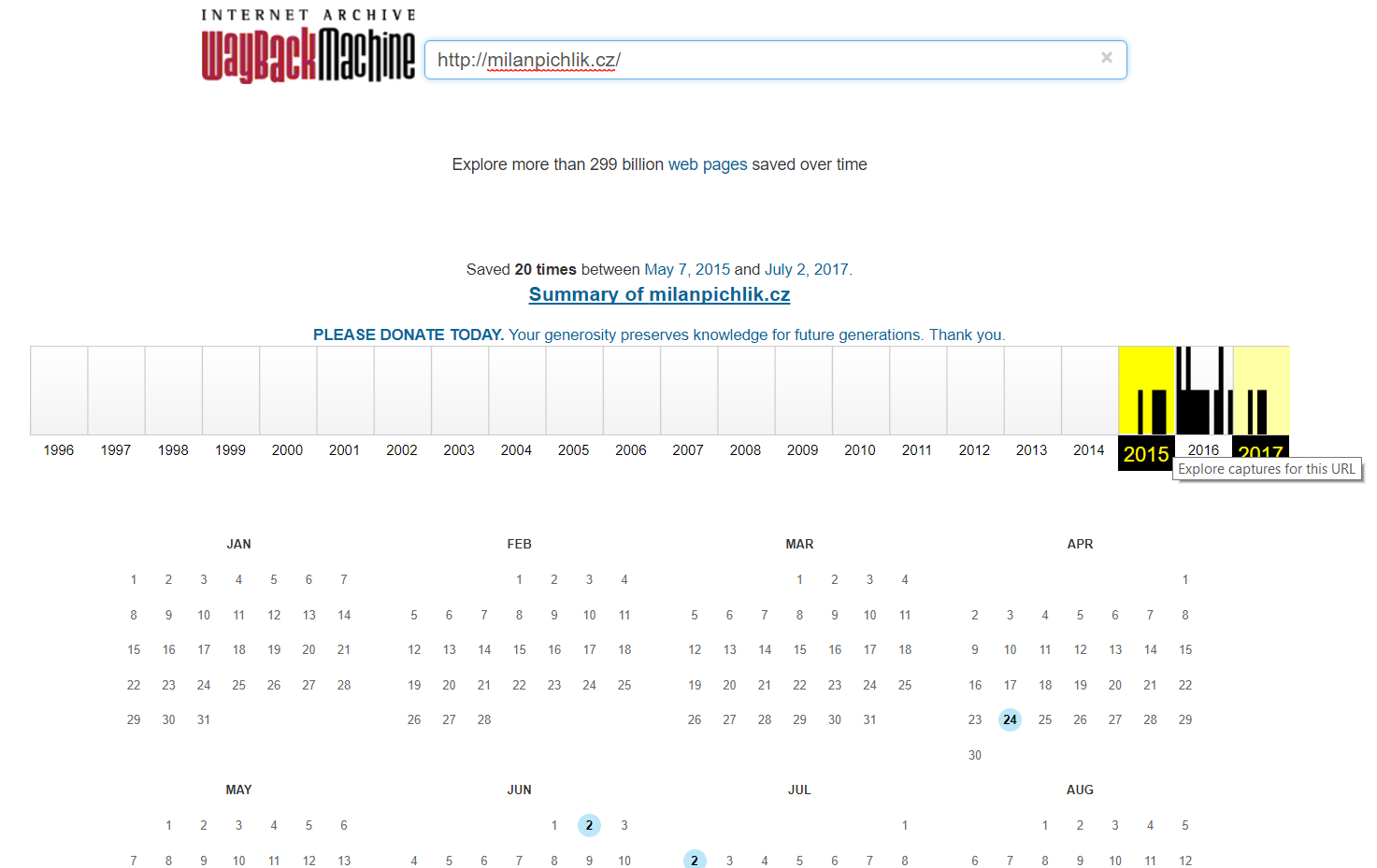
Zde si dejte obrovský pozor! Opravdu si projděte z každého roku alespoň jeden snapshot. Může se totiž snadno stát, že například od roku 2010 do 2013 tam byl obsah, který je tématický k Vašemu webu. Pak od roku 2014 do 2016 tam byl nějaký erotický obsah. Takové domény bych se obecně vyvaroval, ale scénář může být i lepší. Od roku 2010 do 2013 tam byl například nábytkový magazín a od roku 2014 do 2016 eshop s nábytkem. Tuto analýzu by jste měli provést ještě před koupí domény.
Vaším úkolem je tyto dva druhy webů od sebe oddělit, aby jste získali z každého co nejvíce a ve výsledné rekonstrukci webu se Vám nepřekrývaly přes sebe.
Vyberte první snapshop, na kterém najdete první druh webu. V našem příkladu magazín.
V URL se Vám objevilo číslo. Zkopírujte si ho. Budeme ho potřebovat.

Následně vyberte poslední snapshot, na kterém je stále magazín z našeho příkladu.
V URL se změnilo číslo. Opět si ho zkopírujte.

Jak Vám již asi došlo, tak tato čísla značí časový interval, pro který budeme web exportovat.
Nyní zpátky do Ruby. Pro export webu z daného časového období budete potřebovat tento příkaz:
wayback_machine_downloader https://milanpichlik.cz –from 20160303213735 –to 20170424081134
1. Vložte URL Vaší expirované domény místo názvu mého blogu
2. Vyměňte kódy, které jste si poznamenali z postupu výše
Tento příkaz vložte do Ruby a sledujte tu magii.
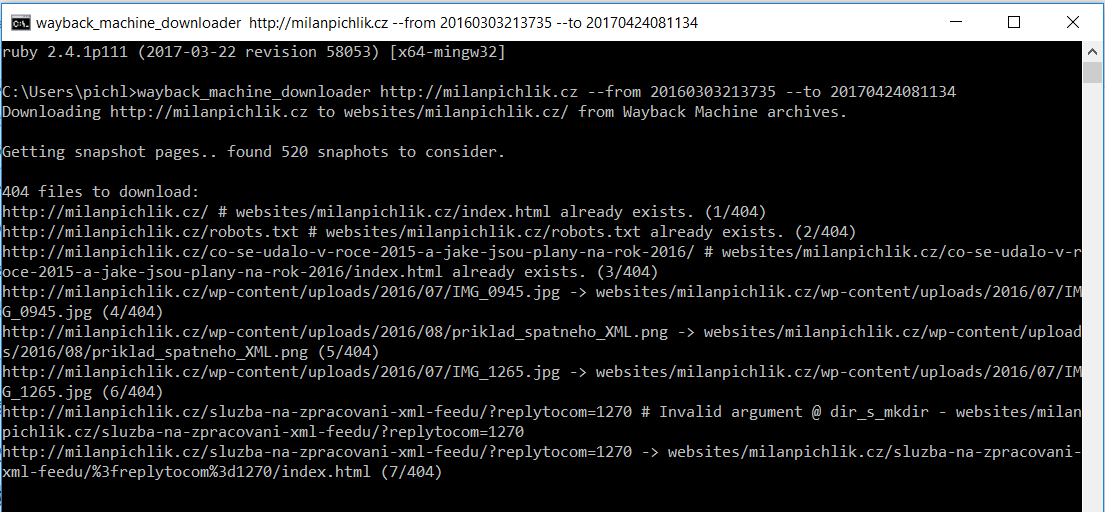
Nyní si v klídečku zajděte na kafe. Skript stahuje veškeré soubory z časového rozpětí, které jste si zvolili. Mohou to být až tisíce souborů. Stahování není zrovna rychlé, takže to může nějakou dobu trvat.
V pauze při stahování se také koukněte na další příkazy, které se mohou při stahování expirované domény hodit.
-d, --directory PATH Directory to save the downloaded files into
Default is ./websites/ plus the domain name
-f, --from TIMESTAMP Only files on or after timestamp supplied (ie. 20060716231334)
-t, --to TIMESTAMP Only files on or before timestamp supplied (ie. 20100916231334)
-e, --exact-url Download only the url provied and not the full site
-o, --only ONLY_FILTER Restrict downloading to urls that match this filter
(use // notation for the filter to be treated as a regex)
-x, --exclude EXCLUDE_FILTER Skip downloading of urls that match this filter
(use // notation for the filter to be treated as a regex)
-a, --all Expand downloading to error files (40x and 50x) and redirections (30x)
-c, --concurrency NUMBER Number of multiple files to dowload at a time
Default is one file at a time (ie. 20)
-p, --maximum-snapshot NUMBER Maximum snapshot pages to consider (Default is 100)
Count an average of 150,000 snapshots per page
-l, --list Only list file urls in a JSON format with the archived timestamps, won't download anything
-v, --version Display versionMůžete například změnit složku, do které se Vám web stáhne, zakázat některé URL adresy nebo naopak stáhnout pouze některé URL adresy atd. Kompletní využití i s jasnými příklady naleznete přímo na stránkách GitHubu.
Po dokončení Vám skript napíše jak dlouho běžel, a že je vše v pořádku staženo.
Stažený web obvykle najdete zde:
Tento počítač -> Disk C -> Users -> Váš login -> websites -> název expirované domény
Stažený web si otevřete ve Vašem prohlížeči otevřením souboru index.html.

Občas se stane, že mohou chybět nějaké obrázky, javascripty apod. Tzn. web nebude jako ze škatulky, ale to vůbec nevadí. Nám jde o to získat seznam URL adres.
Exportujeme URL pomocí Xenu – 1. způsob
Nyní přichází na řadu ta pravá sranda. Stáhněte si Xenu. Pokud jste s tímto nástrojem nikdy nepracovali, tak mrkněte na tento návod.
Web se Vám v prohlížeči pustil na nějaké takovéto URL adrese:

Tu URL zkopírujte a vložte do Xenu.
Po dokončení procházení klikněte na to, že chcete report.
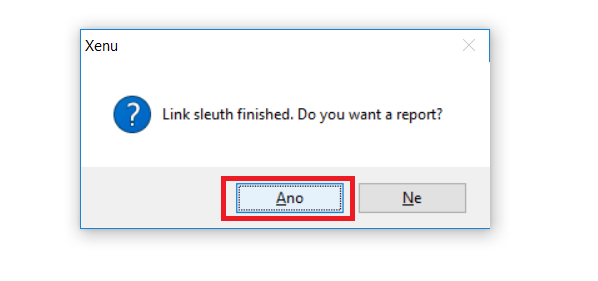
Bingo. V reportu uvidíte všechny možné URL adresy, které na expirované doméně byly a je možné je použít pro přesměrování.

Samozřejmě ne všechny URL adresy musíte použít. Vyberte si ty, které dávají pro Váš projekt nějaký smysl.
Exportujeme URL pomocí Xenu – 2. způsob
Druhou možností je vzít vyexportované soubory z programu a nahrát je přímo na FTP do složky s názvem expirované domény. Poté otevřete doménu v prohlížeči a uvidíte na ní stažený obsah. URL domény pak vložte do Xenu a opět uvidíte seznam URL adres. Tato metoda bývá o něco přesnější. Sice Vám to vyhodí spoustu 404, protože všechny stránky nemají stažený HTML kód – ne každé podstránka má snapshot ve WayBackMachinu.
Nicméně to vůbec nevadí. Stále jste udělali více než 95% lidí, kteří kupují expirované domény.
Stejný postup posléze aplikujte i pro další časové období, pokud na doméně historicky běžely i jiné druhy webů.
Co je možné udělat dál
Se seznamem URL adres se dají dělat další kouzla. Například můžete zjistit jaké konkrétní odkazy vedou na konkrétní URL adresu Vaší expirované domény. Já k tomu opět využiji Majestic.
K tomu postačí nástroj Bulk Backlinks. Do toho vložím seznam URL adres, u kterých chci znát informace o backlinkách.
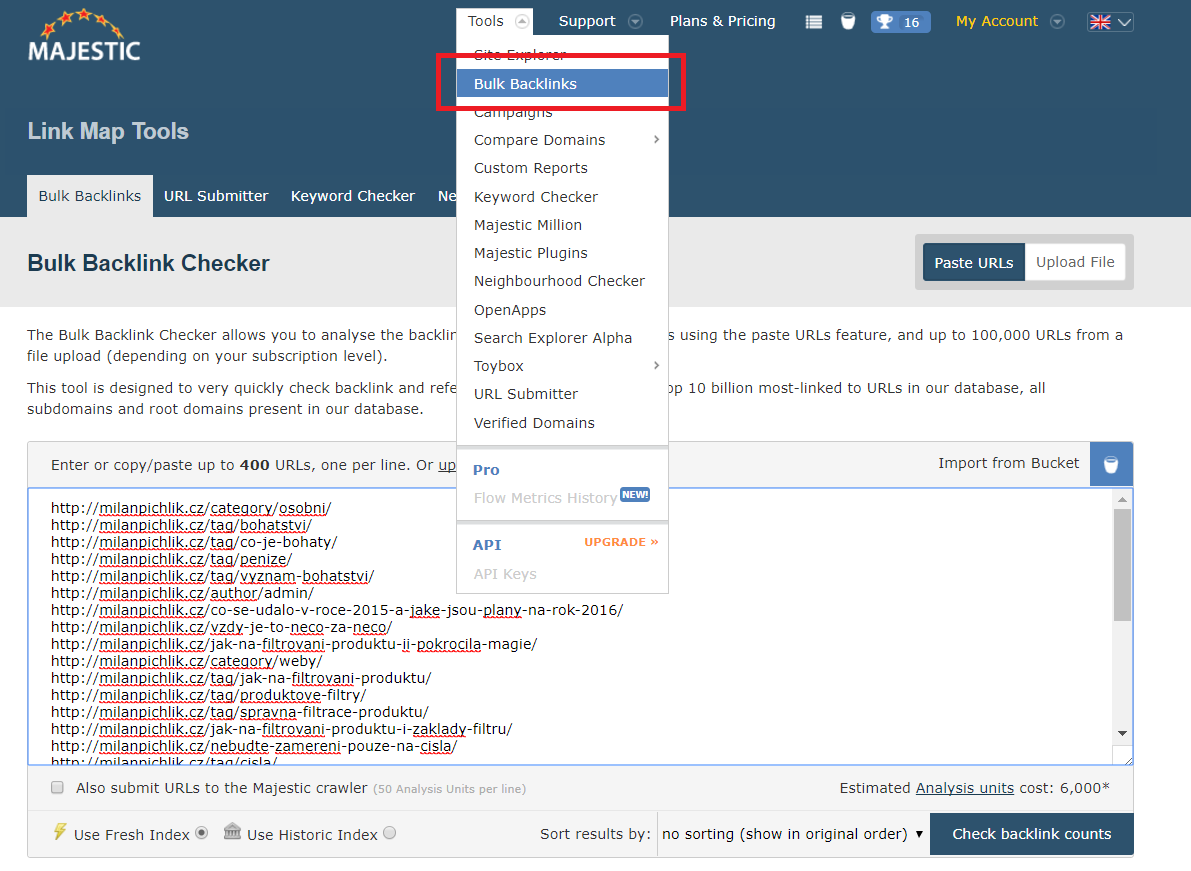
Pak již nezbývá nic jiného než kliknout na Check backlink counts.
Výsledek si můžete vyexportovat například do Excelu, kde krásně uvidíte všechna důležitá data o analyzovaných URL adresách.
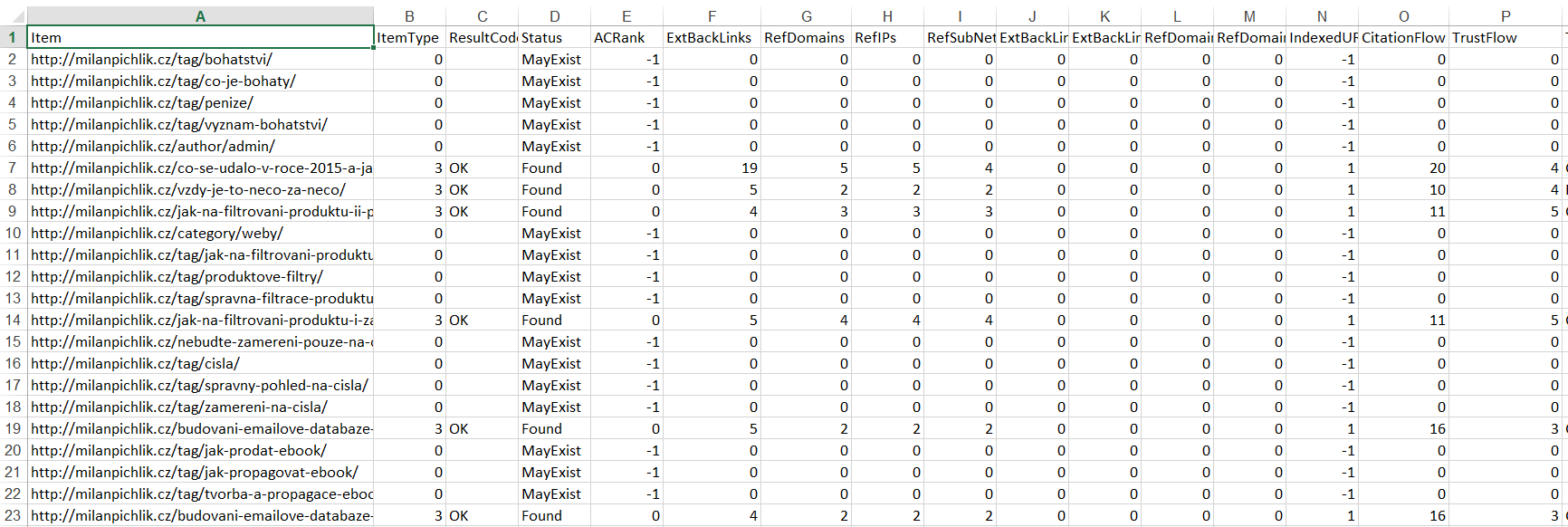
Tyto informace Vám dají představu o tom kolik odkazů redirectem příslušné URL získáte.
Moudrá slova závěrem
Těch způsobů jak dosáhnout podobného výsledku je spousta. Můžete samozřejmě použít i jiné nástroje. Je dost takových, které Vám dají ještě lepší výsledky. Například URL profiler nebo Screaming Frog.
Chci zdůraznit, že kvalita exportu domény z WayBackMachinu závisí hodně na počtu snapshotů a také na tom, zda doména má snapshoty i z různých URL adres a ne jen homepage. Protože z některých URL adres mohou zase vést odkazy na podstránky, které na homepage nejsou. Tím pádem, když máte málo snapshotů, tak se dostanete jen na velice omezené spektrum URL adres. Nicméně jak jsem již napsal. I omezené spektrum URL adres je násobně lepší než jen přesměrovat celou doménu se všemi podstránkami na jedno místo.
Sepsání tohoto návodu mi zabralo poměrně dost času. Snad Vám pomůže zase o kousek vylepšit Vaše pozice ve výsledcích vyhledávání. Pro ještě lepší práci v SEO můžete využít marketingové mapy.
Budu rád, když článek na oplátku zasdílíte nebo alespoň zanecháte ošklivý kritický komentář 🙂

Když si k expirované doméně založíš Search Console, tak se někdy objeví i historická data. Může to být alternativa k tvé metodě, jen hodně nejistá, jsou to výjimky v řádech jednotek procent.
Jinak super článek, fandím takovým návodům, zvláště z oblastí, které jsou mi blízké.
Dobrá poznámka. Díky za ní. Snad to pomůže k lepším výsledkům 🙂
Milane, tohle se mi bude hodit. Dlouho jsem přemýšlel jak na rekonstrukci obsahu z Wayback a tohle řešení mi uniklo. Super, díky.
Rádo se stalo, ale v článku chybí jedna podmínka. V SERPu musíš být vždy až zamnou, když tuhle metodu použiješ 😀
Super přínosný článek Milane, díky za něj 🙂
Neexistuje náhodou i nějaká free/levnější varianta Majesticu, pro zjištění zpětných odkazů?
Díky
Jirka
Jasně, existuje tento nástroj – http://www.backlinkwatch.com/.
Není to však nic čupr dupr s čím by se dalo dobře pracovat. Opravdu doporučuji zainvestovat do Majesticu, je to super nástroj. I když trochu dražší 🙂
Ať se daří.
M.
Ahoj Milane, díky moc za super článek. Nějak akorát bojuju s chybou v Ruby – když tam dám ten příaz jak píšeš, ta mi to píše tohle:
wayback_machine_downloader není názvem vnitřního ani vnějšího příkazu,
spustitelného programu nebo dávkového souboru.
Tady je print screen: https://ctrlv.cz/H8WU
Zkoušel jsm různé kombinace příkazů, i ten tvůj příkaz jak máš v článku a postupoval podle návodu a nějak to nefachčí:( Nevíš co s tím?
Dík moc za pomoc,
Tomáš
Ahoj ahoj,
díky za komentář. Tohle je moje chyba, protože v článku chyběl jeden step. Jak toho bylo hodně, tak jsem na něj zapomněl…
Než zadáš stahování přes ten WayBack Machine Downloader, tak ho napřed musíš přes Ruby nainstalovat.
To se provádí tímto příkazem: gem install wayback_machine_downloader
Máš to již doplněné v článku. Myslím, že je to je ten důvod proč ti to nejde.
Kdyby ještě dál něco nefungovalo, tak dej vědět. Rád poradím.
Milan
Super, už to fachčí, díky moc!
Ahoj Milane, díky za super článek a tip na Rubyho. Mám k tomu ale pár pochybností.
Je to regulérní BlackHat metoda, proto mě zajímá, jestli sis už touto technikou přivábil penalizaci – případně za jakých okolností.
Historie bez spamu, důvěryhodný odkazový profil a tematičnost jsou jasné východiska. Co ale indexované stránky na Google?
1) Má cenu přesměrovat i domény, které už jsou dlouho deindexované? (v SERPu nenajdeš ani zmínku)
2) Kolik domén maximálně jsi takto přesměroval např. během měsíce?
Díky moc a ať se daří
Blackhat metoda? Nemyslím si, že je to blackhat metoda. Efektivně využíváš odkazový profil domény, která by už třeba upadla v zapomnění a nikdo by jí nikdy nepoužil. Využíváš odkazy co má. Nic nemanipuluješ.
Stránky indexované na Google z něj jednoduše často vypadnout pokud na doméně změníš obsah. Jen to chvíli potrvá.
1) Ano, má pokud mají dobrý odkazový profil a ty odkaz stále existují.
2) Nevím, těžko říct, nevedu si evidenci 😀
Ať se také daří.
Milan
Ahoj Milane,
přesměrováváš tedy jen pro tebe zajímavé URL? Co se zbytkem? Přesměruješ na HP nebo necháš ležet ladem?
Přesměrování provádíš přes htaccess? Mohl by jsi sem prosím dát nějaký vzorový, jak je to správně? Je více způsobů a těžko říct, který je ,,seo správně´´.
Ahoj, snažím se přesměrovat co nejvíce je možné. Pokud je nějaká URL úplně mimo a i obsah je nesmyslný, tak jí přesměrovávám na homepage. Jinak je to opravdu z mého pohledu o té mravenčí práci dostat co nejvíce URL na to nejvhodnější místo.
Přesměrování dělám buď přes plugin 301 redirection ve WordPressu a nebo přímo přes htaccess. Pokaždé však jiným způsobem podle náročnosti. Nemám na to univerzální mustr 🙂
Milan
Ahoj, mám k tomuto tématu jeden dotaz. Používáš pak na webu přesně ten obsah a HTML kód, který stáhneš pomocí těchto nástrojů? Trochu bych se bál toho, že se pak někdo ozve kvůli autorským právům na texty, HTML kód, obrázky, apod. Nebál ses toho? 🙂
Takových věcí se nebojím. Pokud se někdo ozve a jsou to rozumné argumenty, tak problematický obsah stáhnu. Kdo se bojí nesmí do lesa 🙂
Zdravím, zjistil jsem, že k mé stránce existuje velké množství starých odkazů z předchozí stránky o které jsem ani nevěděl. Poradíte mi, zda je vhodné je přesměrovat na domovskou stránku popř. jak? Nejde mi o vytváření stejných odkazů ani receptů. Jsem schopen odkazy získat v search console jen nevím jak je využít ve svůj prospěch. Předem díky 🙂 BTW: super návod
Jde nějak vyexportovat clanky, nebo proste obsah z webu co je na web.archive.org? Nahazuju clanky pojednom, ale nejak hromadne by to bylo lepsi.